Introduction and Background
From Minimax to AlphaZero
The minimax engine plays well, but is fundamentally limited: every heuristic is hand-crafted and hand-tuned. The evaluation function assigns fixed scores to patterns — open threes, closed fours, capture threats — based on playtesting. It cannot adapt, learn from mistakes, or improve on its own. Adding capture rules to the game required manually retuning dozens of score constants.
AlphaZero (Silver et al., 2018) demonstrated a different approach: a neural network combined with Monte Carlo Tree Search can learn to play from self-play alone, with zero domain-specific evaluation knowledge beyond the rules of the game. The network replaces both the evaluation function (via the value head) and move ordering (via the policy head). The result is a system that improves by playing against itself.
Learning Path
The implementation started from reading the AlphaGo paper (Silver et al., 2016) and the AlphaZero paper (Silver et al., 2018). The practical starting point came from foersterrobert's AlphaZero tutorial (YouTube) and the AlphaZeroFromScratch repository, which provided a working reference implementation for small boards.
Sequential and vectorize search modes were implemented based on this tutorial. From there, the system was extended with multiprocess search and Ray distributed training to handle the computational demands of a 19x19 board with custom rules (captures, double-three).
The original implementation (in a separate repository) worked for small boards but revealed data integrity issues at scale. This motivated a complete architectural refactoring that produced the current modular codebase — separating the game engine, MCTS, training pipeline, and inference into distinct packages with well-defined interfaces.
Architecture Overview
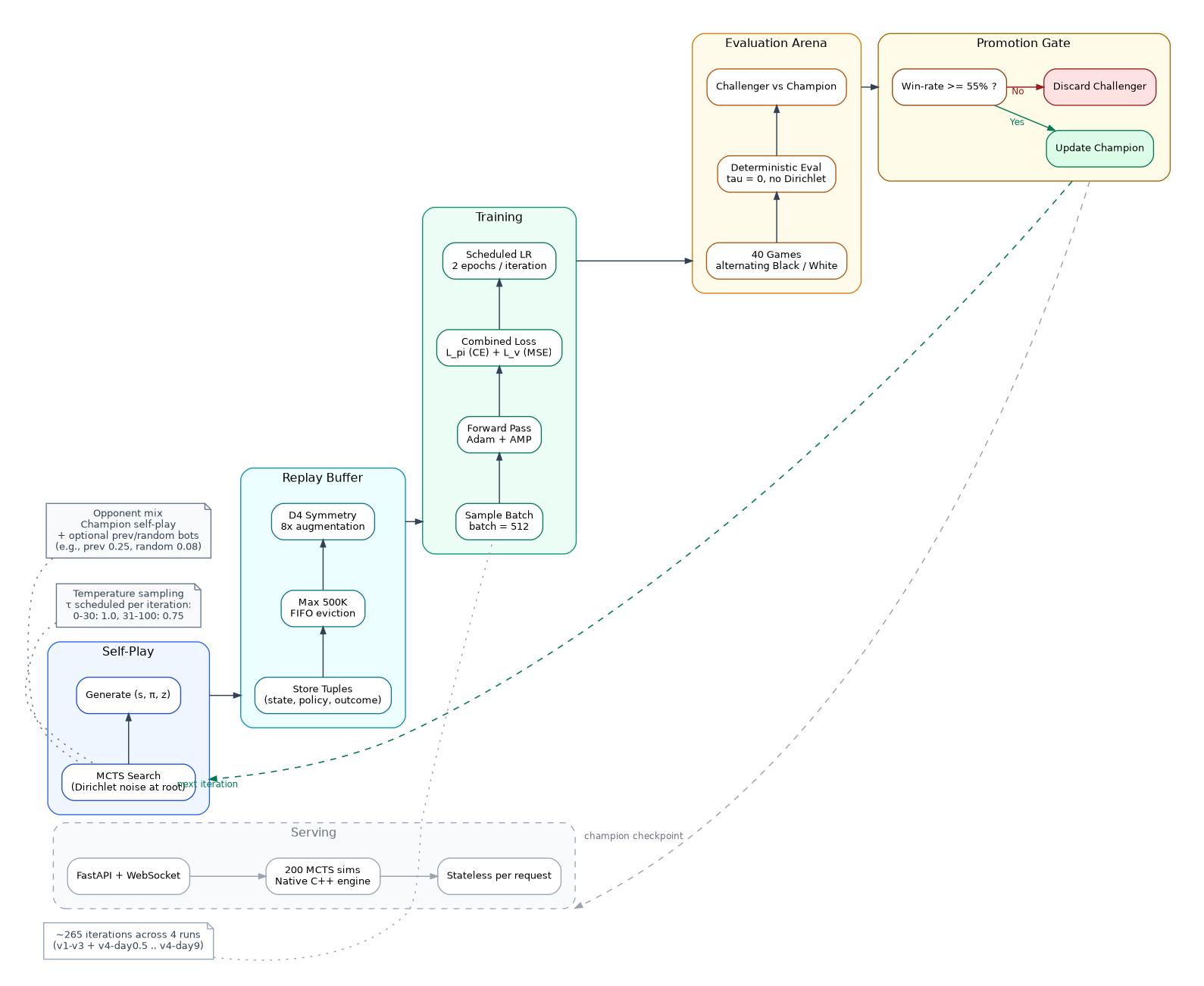
The system consists of five major components that form the AlphaZero training and serving loop:
 - AlphaZero training loop diagram -
- AlphaZero training loop diagram -
- Game Engine (
gomoku/core/) — rules, state management, capture detection, double-three validation - Neural Network (
gomoku/model/) — ResNet policy-value network producing move probabilities and position evaluation - MCTS (
gomoku/pvmcts/) — tree search guided by the network, with four interchangeable backends: Sequential, Vectorize, Multiprocess, and Ray (see Search Engine Architecture) - Training Pipeline (
gomoku/alphazero/) — self-play game generation, replay buffer, gradient updates, evaluation, model promotion - Serving Layer (
server/) — FastAPI + WebSocket, loads a trained checkpoint and runs MCTS per request
Key Numbers
- 19x19 board, 361 possible actions per turn
- 128-channel ResNet with 12 residual blocks
- 13-channel state encoding: current player stones, opponent stones, empty cells, last move, capture scores (×2), color plane, forbidden points, and 5 move history planes
- 200 to 2400 MCTS simulations per move during training, 200 in production (native C++)
- V4 production run: 222 completed training iterations on GCP Ray cluster (265 total across V1-V4)
- The system went through four GCP training runs (V1–V4) before producing the current champion. The full progression — including hyperparameter failures, a mid-training rule bug, and engineering takeaways — is documented in Training History, Deployment, and Lessons Learned.