Training Pipeline and GCP Infrastructure
Self-Play Loop
Each training iteration begins with the current champion model playing games against itself to generate training data. Each game produces a sequence of tuples: the board state , the MCTS policy (normalized visit counts at the root), and the eventual game outcome ( win, loss, draw).
Games are played with exploration enabled: Dirichlet noise at the root ensures the search doesn't collapse to a single line of play, and temperature for a configurable number of opening moves (set by scheduled exploration_turns) produces diverse opening positions. After the exploration phase, temperature drops to 0 (deterministic play) for the remainder of the game.
Opponent diversity prevents overfitting to a single play style. The self-play mix is configurable — for example, 5% random bot, 30% previous champion, 65% current champion — ensuring the training data covers a range of opponent strengths.
Terminal-check simplification: AlphaZero's game engine treats any contiguous five-in-a-row as terminal without checking whether the opponent could immediately break the alignment via capture. The frontend enforces the stricter breakable-five rule, so a rare edge case exists where the AI considers a position won that the frontend would not. In practice, breakable fives are uncommon enough that training quality is not materially affected.
Replay Buffer and Data Augmentation
Game records are stored as Parquet shards — a columnar format efficient for large datasets with mixed types (board as int8 buffer, policy as float16). The replay buffer holds up to 500K samples with FIFO eviction, and training only begins after a minimum sample count is reached.
D4 symmetry augmentation is the most impactful data engineering decision. The 19x19 board has 8 symmetries under the dihedral group : 4 rotations (, , , ) times 2 reflections (original and horizontally flipped). In this implementation, one of the 8 transforms is sampled each time a training sample is loaded:
Source: alphazero/gomoku/alphazero/learning/dataset.py:63-86
# alphazero/gomoku/alphazero/learning/dataset.py:63-86
def _apply_symmetry(
encoded_state: np.ndarray, policy: np.ndarray, game: Gomoku
) -> tuple[np.ndarray, np.ndarray]:
"""Apply a random D4 symmetry to the encoded state and policy."""
h, w = game.row_count, game.col_count
if policy.size != h * w:
return encoded_state, policy
k = int(np.random.randint(0, 8))
obs = encoded_state
pi_2d = policy.reshape(h, w)
if k >= 4:
obs = np.flip(obs, axis=2) # horizontal flip on width axis
pi_2d = np.flip(pi_2d, axis=1)
k -= 4
if k > 0:
obs = np.rot90(obs, k=k, axes=(1, 2))
pi_2d = np.rot90(pi_2d, k=k)
obs = np.ascontiguousarray(obs)
pi_flat = np.ascontiguousarray(pi_2d.reshape(-1))
return obs, pi_flat
pythonThis gives eight symmetry-equivalent views over time without additional self-play compute — critical for data efficiency when GPU time is expensive.
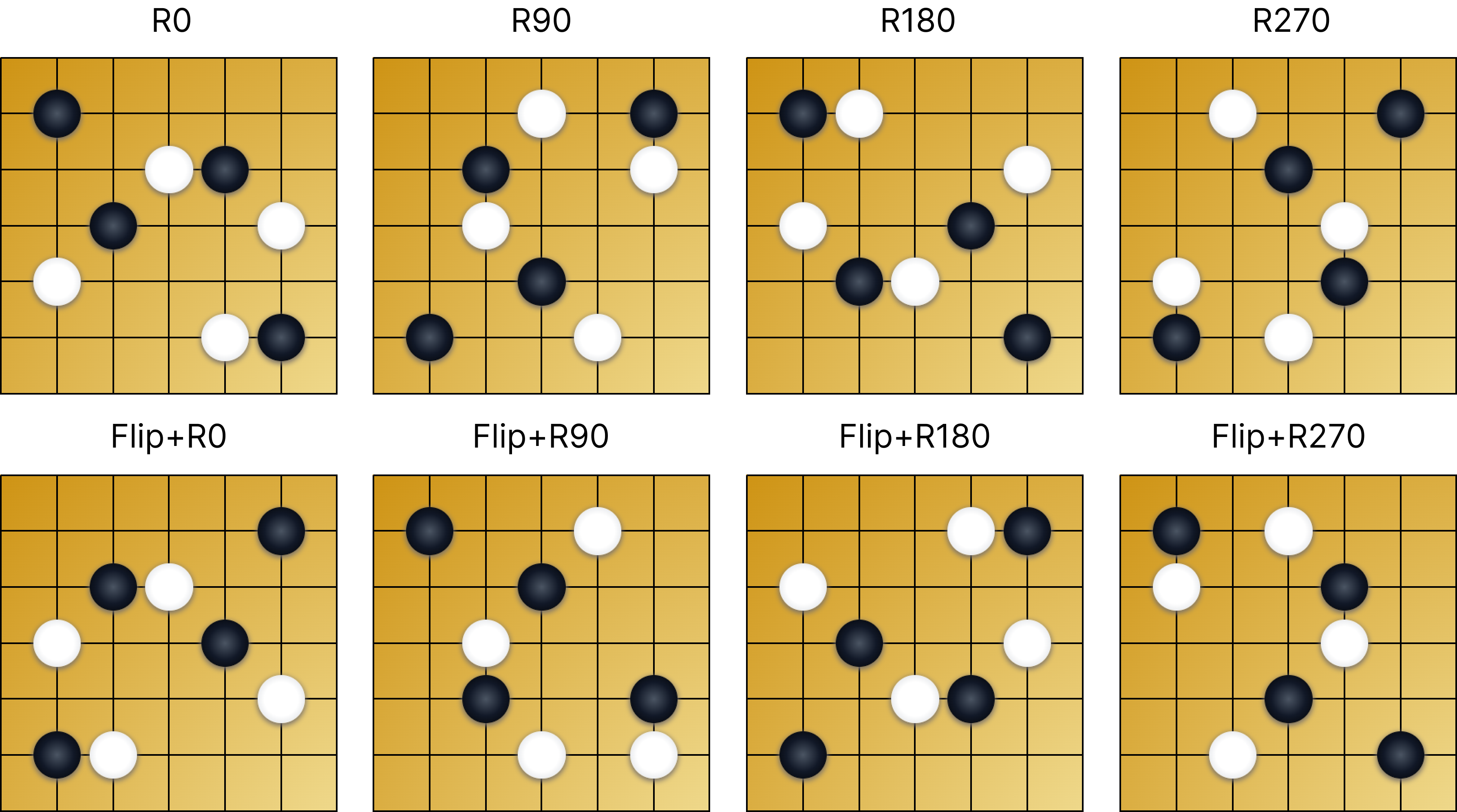 - D4 symmetry augmentation -
- D4 symmetry augmentation -
Prioritized Experience Replay (PER)
In the current implementation, PER is activated when training.priority_replay.enabled: true. When active, samples are weighted by prediction error so positions where the model was most wrong are sampled more frequently:
where is the priority (TD-error + ), controls how strongly priorities affect sampling, and is the importance-sampling correction weight that prevents biased gradient updates. In practice, the weights are normalized by the maximum weight in each batch () to keep gradient magnitudes stable.
A critical design requirement: PER only works if sample priorities are updated after each training batch based on the prediction error from that batch. Without this update, the priority weighting becomes stale and provides no benefit — it's just random sampling with extra overhead. The implementation updates priorities in-place:
Source: alphazero/gomoku/alphazero/learning/trainer.py:221-235
# alphazero/gomoku/alphazero/learning/trainer.py:221-235
# Update PER priorities with fresh TD-error estimates
if use_per and getattr(dataset, "priorities", None) is not None:
with torch.no_grad():
td_errors = torch.abs(
out_value.detach().squeeze() - value_targets.detach().squeeze()
)
new_priorities = (td_errors + per_eps).cpu().tolist()
if getattr(dataset, "return_index", False):
for idx_val, p_val in zip(batch_indices, new_priorities, strict=False):
dataset.priorities[int(idx_val)] = _safe_priority(float(p_val))
pythonTraining Loop
In the production V4 run, each iteration used 2 epochs over the replay buffer. This is configurable via training.num_epochs in YAML. Batch size 512, AMP (automatic mixed precision) for GPU efficiency, Adam optimizer with scheduled learning rate.
The loss combines value MSE and policy cross-entropy. Here, out_policy is the raw policy logits from the network, and log_softmax converts them into log-probabilities for the cross-entropy term:
Source: alphazero/gomoku/alphazero/learning/trainer.py:184-203
# alphazero/gomoku/alphazero/learning/trainer.py:184-203
# Policy: cross-entropy with MCTS visit targets
log_probs = F.log_softmax(out_policy, dim=1)
policy_losses = -(policy_targets * log_probs).sum(dim=1)
# Value: MSE between prediction and game outcome
value_losses = F.mse_loss(
out_value.squeeze(), value_targets.squeeze(), reduction="none"
)
# Combined
combined_losses = policy_losses + value_losses
loss = combined_losses.mean()
pythonL2 regularization is configured through Adam weight_decay (cfg.training.weight_decay) when building the optimizer.
Scheduled Parameters
Many hyperparameters change over the course of training. The config system (Pydantic models) supports scheduled values — parameters that vary by training iteration:
Source: alphazero/configs/
# alphazero/configs/ — example scheduled parameter
learning_rate:
- { until: 30, value: 0.002 }
- { until: 137, value: 0.0008 }
yamlThis enables learning rate warmup/decay, increasing MCTS simulations as the model improves, and temperature annealing — all configured declaratively in YAML without code changes.
GCP Training Infrastructure
Training ran on a GCP Ray cluster with GPU workers. Ray handles distributed self-play: multiple CPU workers generate games in parallel, sending inference requests to GPU actors via the async pipeline described in Search Engine Architecture.
Training progression observations: The model started exhibiting blocking behavior (defending against opponent threats) around training day 3 of the elo1800-v4 run. As iterations progressed, it developed aggressive play patterns — including creating open threes (3-3 patterns) that force the opponent into defensive positions. The current champion model plays recognizably strategic Gomoku.
Data is stored in GCS and checkpoints are saved per iteration. The manifest (manifest.json) tracks training metadata, promotion history, and config snapshots for reproducibility — making it possible to resume training or audit any iteration's state.