The Policy-Value Network
Dual-Head Architecture
A single convolutional neural network processes the board state and produces two outputs simultaneously:
- Policy head: 361 unnormalized logits (one score per action)
- Value head: a scalar in predicting game outcome from the current player's perspective ( win, draw, loss)
This replaces both components of classical minimax: the evaluation function (value head) and move ordering (policy head). The combined loss function trains both heads jointly:
where is the game outcome from the current player's perspective ( win, draw, loss), is the predicted value, is the MCTS policy (normalized visit counts), is the network's policy distribution, and is L2 regularization. The first term pushes the value head to predict game outcomes; the second term pushes the policy head to match the MCTS-refined move distribution.
In implementation, the policy head outputs logits. During search, illegal moves are masked and softmax is applied to convert logits into priors. During training, cross-entropy is computed with log_softmax(out_policy).
The L2 regularization term is applied through optimizer weight_decay in the training setup, rather than being added as a separate explicit term inside the trainer step.
ResNet Architecture
The network follows a shared-backbone, dual-head design:
- Input and stem: The
13x19x19state tensor is lifted into a 128-channel feature space by a3x3convolution, followed by batch normalization and ReLU. - Backbone: 12 residual blocks repeatedly refine shared features while preserving information flow through skip connections (
x + F(x)). - Policy head (move selection): A lightweight
1x1convolution and linear projection convert shared features into logits over all 361 actions. - Value head (position evaluation): A
1x1convolution compresses shared features, then a two-layer MLP (361 -> 256 -> 1for a 19x19 board) outputs a scalar throughtanh, producing a value in[-1, 1].
In this implementation, policy_channels = 2 and value_channels = 1.
Source: alphazero/gomoku/model/policy_value_net.py:105-148
# alphazero/gomoku/model/policy_value_net.py:105-148
self.start_block = nn.Sequential(
nn.Conv2d(num_planes, num_hidden, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(num_hidden),
nn.ReLU(),
)
self.res_blocks = nn.ModuleList([ResBlock(num_hidden) for _ in range(num_resblocks)])
self.policy_head = nn.Sequential(
nn.Conv2d(num_hidden, policy_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(policy_channels),
nn.ReLU(),
nn.Flatten(),
nn.Linear(policy_channels * conv_out, game.action_size),
)
self.value_head = nn.Sequential(
nn.Conv2d(num_hidden, value_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(value_channels),
nn.ReLU(),
nn.Flatten(),
nn.Linear(value_channels * conv_out, VALUE_HEAD_FC_UNITS),
nn.ReLU(),
nn.Linear(VALUE_HEAD_FC_UNITS, 1),
nn.Tanh(),
)
def forward(self, x):
x = self.start_block(x)
for res_block in self.res_blocks:
x = res_block(x)
policy_logits = self.policy_head(x)
value = self.value_head(x)
return policy_logits, value
pythonThe original AlphaZero paper used 256 channels and 20 residual blocks with TPU-scale compute. 128 channels and 12 blocks is the balance point for the available GPU budget while still providing sufficient model capacity for 19x19 Gomoku.
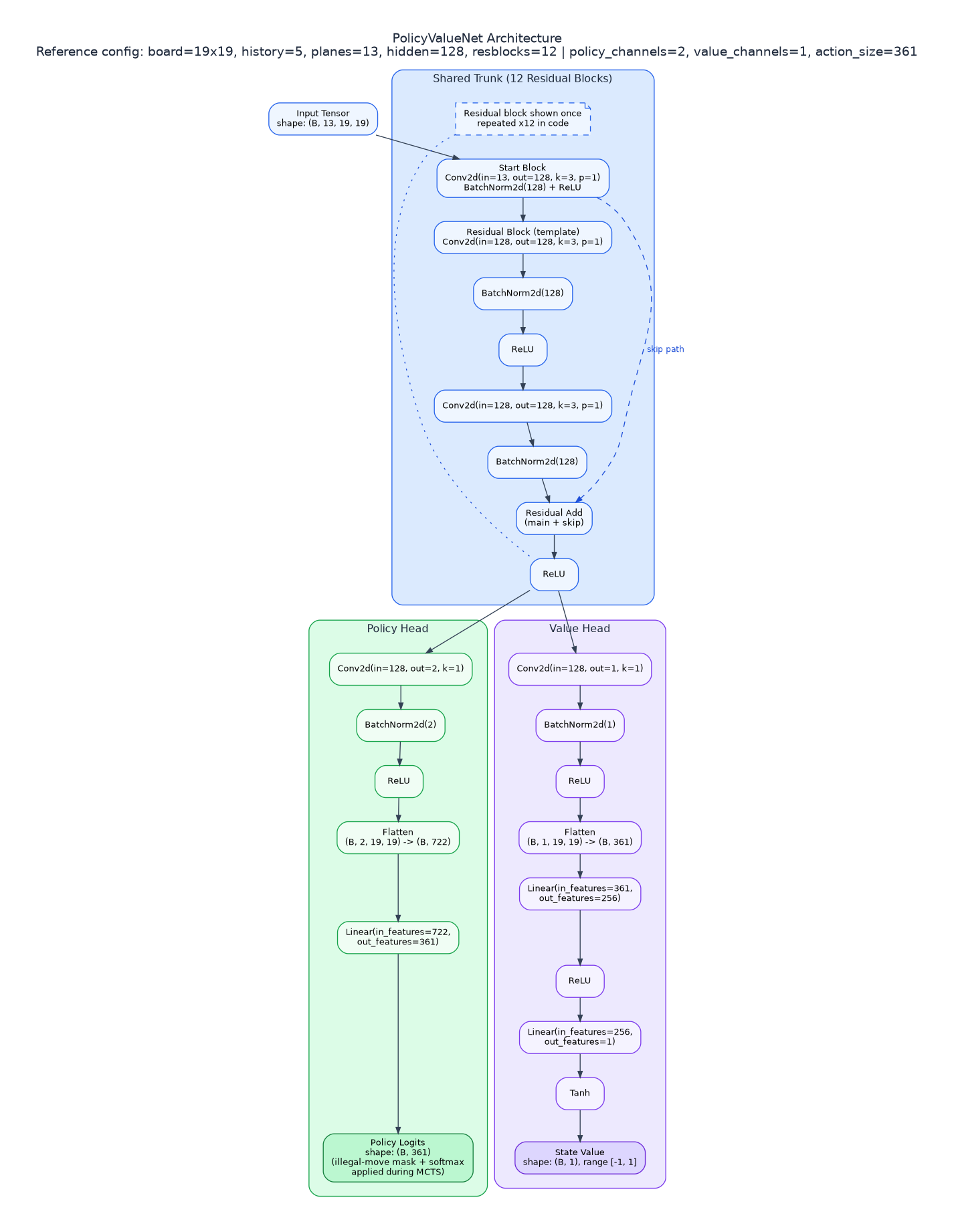 - PolicyValueNet architecture diagram -
- PolicyValueNet architecture diagram -
State Encoding
With the default history_length=5, the network sees a 13-channel tensor (8 + history_length), each channel being a 19x19 binary or scalar plane:
| Channels | Description |
|---|---|
| 0 | Current player's stones (binary) |
| 1 | Opponent's stones (binary) |
| 2 | Empty positions (binary) |
| 3 | Last move indicator (one-hot) |
| 4 | Current player's capture score (ratio, clipped 0–1) |
| 5 | Opponent's capture score (ratio, clipped 0–1) |
| 6 | Color indicator (1.0 for Black, -1.0 for White) |
| 7 | Forbidden move mask (double-three positions, binary) |
| 8–12 | Move history (last 5 moves as one-hot planes) |
Source: alphazero/gomoku/core/gomoku.py:398-463
# alphazero/gomoku/core/gomoku.py:398-463 (get_encoded_state, simplified — intermediate variables inlined for readability)
features = np.zeros((batch_size, 8 + self.history_length, h, w), dtype=np.float32)
# Base occupancy planes
features[:, 0] = boards == next_players[:, None, None]
features[:, 1] = boards == (3 - next_players)[:, None, None]
features[:, 2] = boards == EMPTY_SPACE
# Last move one-hot plane
if valid_idx.size:
features[valid_idx, 3, ys, xs] = 1.0
# Capture progress planes (normalized 0..1)
if self.enable_capture and self.capture_goal > 0:
features[:, 4] = my_ratio[:, None, None]
features[:, 5] = opp_ratio[:, None, None]
# Color plane (+1 black, -1 white)
features[:, 6] = color_vals[:, None, None]
# Forbidden points for current player (double-three)
if self.enable_doublethree:
for b_idx in range(batch_size):
empties = np.flatnonzero(boards[b_idx] == EMPTY_SPACE)
xs, ys = bulk_index_to_xy(empties, self.col_count)
for x, y in zip(xs, ys, strict=False):
if detect_doublethree(
boards[b_idx], int(x), int(y), int(next_players[b_idx]), self.row_count
):
features[b_idx, 7, int(y), int(x)] = 1.0
# Move history planes (one-hot per past move)
hist_buffer = np.full((batch_size, self.history_length), -1, dtype=np.int32)
for idx, st in enumerate(states):
if st.history:
capped = st.history[: self.history_length]
hist_buffer[idx, : len(capped)] = capped
start_ch = 8
for k in range(self.history_length):
moves = hist_buffer[:, k]
valid = moves >= 0
if not np.any(valid):
continue
xs = moves[valid] % self.col_count
ys = moves[valid] // self.col_count
features[valid, start_ch + k, ys, xs] = 1.0
pythonThis encoding gives the network everything it needs: the current position, game-specific context (captures, forbidden moves), temporal context (move history), and player identity. The capture score channels are particularly important for this Gomoku variant — they tell the network how close each player is to the 5-pair capture win condition.
The get_encoded_state method supports batch encoding and has an optional native C++ encoding path for faster inference in production. D4 symmetry augmentation is applied in the training dataset pipeline (ReplayDataset), not inside get_encoded_state.